
It is amazing the number of things machines can be trained to do – from voice recognition to navigation to even playing chess! But for them to achieve these incredible feats, a significant amount of time is put into training them to recognize patterns and relationships between variables. This is the essence of machine learning. Large volumes of data are fed to computers for training, validation, and testing. However, for machine learning to take place, these data sets must be curated and labeled to make the information easier for them to understand; a process known as data annotation.
What is Data Annotation?
Data annotation is the process of making text, audio, or images of interest understandable to machines through labels. It is an essential part of supervised learning in artificial intelligence. For supervised learning, the data must be trained to enhance the machine’s understanding of the desired task at hand.
Take for instance that you want to develop a program to single out dogs in images. You must go through the rigorous process of feeding it with multiple labeled pictures of dogs and “non-dogs” to help the model learn what dogs look like. The program will then be able to compare new images with its existing repository to find out whether an image contains a dog in it.
Though the process is repetitive at the beginning, if enough annotated data is fed to the model, it will be able to learn how to identify or classify items in new data automatically without the need of labels. For the process to be successful, high quality annotated data is required. This is why most developers choose to use human resources for the annotation process. The process might be automatized by using a machine to prepopulate the data, but a human touch and a human eye is preferred for review when the data is nuanced or sensitive. The higher the quality of annotated data fed to the training model, the higher the quality of the output. It is also important to note that most AI algorithms require regular updates to keep up with changes. Some may be updated as often as every day.
Types of Annotation in Machine Learning
1. Text annotation

Text annotation is the process of attaching additional information, labels, and definitions to texts. Since written language can convey a lot of underlying information to a reader such as emotions, sentiment, stance, and opinion, in order for a machine to identify that information, we need humans to annotate what exactly it is in the text data that conveys that information.
Natural language processing (NLP) solutions such as chatbots, automatic speech recognition, and sentiment analysis programs would not be possible without text annotation. To train NLP algorithms, massive datasets of annotated text are required.
How is text annotated?
Most companies seek out human annotators to label text data. With language being very subjective, it is often best to utilize the help of highly-skilled human annotators who provide significant value especially in emotional and subjective texts. They are familiar with modern trends, slang, humor and different uses of conversation.
First, a human annotator is given a group of texts, along with pre-defined labels and client guidelines on how to use them. Next, they match those texts with the correct labels. Once this is done on large datasets of text, the annotations are fed into machine learning algorithms so that the machine can learn when and why each label was given to each text and learn to make correct predictions independently in the future. When built correctly with accurate training data, a strong text annotation model can help you automate repetitive tasks in a matter of seconds.
Below, we’ve laid out different types of text annotation and how each one is used in the business world.
a) Sentiment Annotation
Sentiment annotation is the evaluation and labeling of emotion, opinion, or sentiment within a given text. Since emotional intelligence is subjective – even for humans – it is one of the most difficult fields of machine learning. It can be challenging for machines to understand sarcasm, humor, and casual forms of conversation. For example, reading a sentence such as: “You are killing it!”, a human would understand the context behind it and that it means “You are doing an amazing job”. However, without any human input, a machine would only understand the literal meaning of the statement.

When built correctly with accurate training data, a strong sentiment analysis model can help businesses by automatically detecting the sentiment of:
- Customer reviews
- Product reviews
- Social media posts
- Public opinion
- Emails
b) Text Classification
Text classification is the analysis and categorization of a certain body of text based on a predetermined list of categories. Also known as text categorization or text tagging, text classification is used to organize texts into organized groups.

- Document classification – the classification of documents with pre-defined tags to help with organizing, sorting, and recalling of those documents. For example, an HR department may want to classify their documents into groups such as CVs, applications, job offers, contracts, etc.
- Product categorization – the sorting of products or services into categories to help improve search relevance and user experience. This is crucial in e-commerce, for example, where annotators are shown product titles, descriptions, and images and are asked to tag them from a list of departments the e-commerce store has provided.
c) Entity Annotation
Entity annotation is the process of locating, extracting and tagging certain entities within text. It is one of the most important methods to extract relevant information from text documents. It helps recognize entities by giving them labels such as name, location, time and organization. This is crucial in enabling machines to understand the key text in NLP entity extraction for deep learning.

- Named Entity Recognition – the annotation of entities with named tags (e.g. organization, person, place, etc.) This can be used to build a system (a Named Entity Recognizer) that can automatically find mentions of specific words in documents.
- Part-of-speech Tagging – the annotation of elements of speech (e.g. adjective, noun, pronoun, etc.)
- Language Filters – For example, a company may want to label abusive language or hate speech as profanity. That way, companies can locate when and where profane language was used and by whom, and act accordingly.
2. Image annotation

This aim of image annotation is to make objects recognizable through AI and ML models. It is the process of adding pre-determined labels to images to guide machines in identifying or blocking images. It gives the computer, vision model information to be able to decipher what is shown on the screen. Depending on the functionality of the machine, the number of labels fed to it can vary. Nonetheless, the annotations must be accurate to serve as a reliable basis for learning.
Here are the different types of image annotation:
a. Bounding boxes
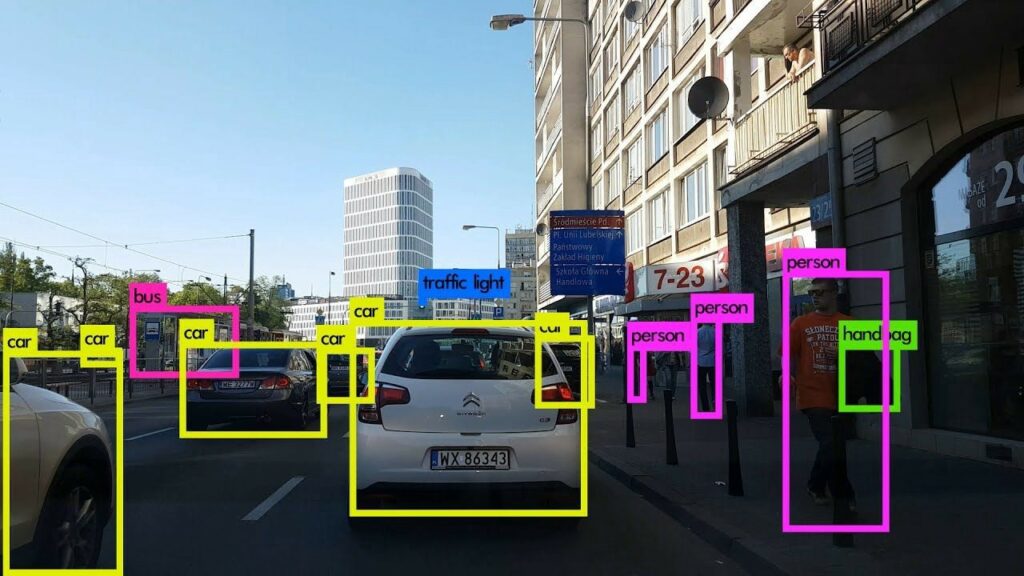
This is the most commonly used type of annotation in computer vision. The image is enclosed in a rectangular box, defined by x and y axes. The x and y coordinates that define the image are located on the top right and bottom left of the object. Bounding boxes are versatile and simple and help the computer locate the item of interest without too much effort. They can be used in many scenarios because of their unmatched ability in enhancing the quality of the images.
b. Line annotation

is method, lines are used to delineate boundaries between objects within the image under analysis. Lines and splines are commonly used where the item is a boundary and is too narrow to be annotated using boxes or other annotation techniques.
c. 3D Cuboids
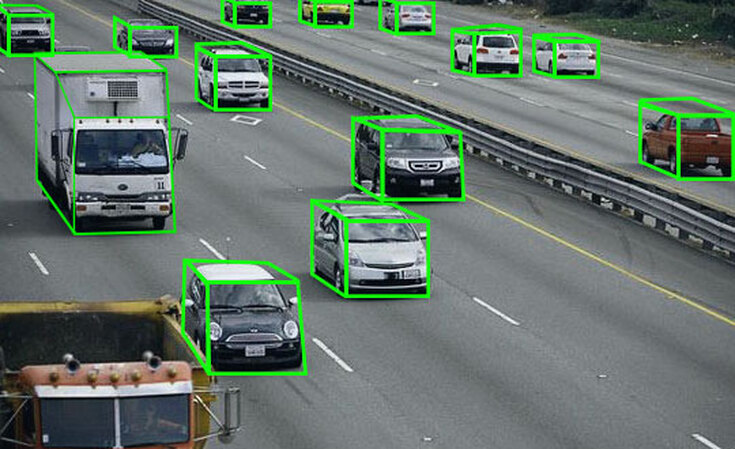
Cuboids are similar to the bounding boxes but with an additional z-axis. This added dimension increases the detail of the object, to allow the factoring in of parameters such as volume. This type of annotation is used in self-driving cars, to tell the distance between objects.
d. Landmark annotation

This involves the creation of dots around images such as faces. It is used when the object has many different features, but the dots are usually connected to form a sort of outline for accurate detection.
3. Image transcription
This is the process of identifying and digitizing text from images or handwritten work. It can also be referred to as image captioning, which is adding words that describe an image. Image transcription relies heavily on image annotation as the prerequisite step. It is useful in creating computer vision that can be used in the medical and engineering fields. With proper training, machines can be able to identify and caption images with ease using technology such as Optical Character Recognition (OCR).
Use Cases of Data Annotation
Improved results from search engines

When building a big search engine such as Google or Bing, adding websites to the platform can be tedious, since millions of web pages exist. Building such resources requires large pools of data that can be impossible to manage manually. Google uses annotated files to speed up the regular updating of its servers.
Large scale data sets can also be fed to search engines to improve the quality of results. Annotations help to customize the results of a query based on the history of the user, their age, sex, geographical location, etc.
Creation of facial recognition software

Using landmark annotation, machines can be able to recognize and identify specific facial markers. Faces are annotated with dots that detect facial attributes such as the shape of the eyes
and nose, face length, etc. These pointers are then stored in the computer database, to be used if the faces ever come into sight again.
The use of this technology has enabled tech companies such as Samsung and Apple to improve the security of their smartphones and computers using face unlock software.
Creation of data for self-driving cars

Although fully autonomous cars are still a futuristic concept, companies like Tesla have made use of data annotation to create semi-autonomous ones. For vehicles to be self-driving, they must be able to identify markers on the road, stay within lane limits, and interact well with other drivers. This can be made possible through image annotation. By making use of computer vision, models can be able to learn and store data for future use. Techniques such as bounding boxes, 3D cuboids and semantic segmentation are used for lane detection, collection, and identification of objects.
Advances in the medical field

New technology in the medical field is largely based on AI. Data annotation is used in pathology and neurology to identify patterns that can be used in making quick and accurate diagnoses. It is also helping doctors pinpoint tiny cancerous cells and tumors that can be difficult to identify visually.
What is the importance of using data annotation in ML?
Improved end-user experience
When accurately done, data annotation can significantly improve the quality of automated processes and apps, therefore enhancing the overall experience with your products. If your websites make use of chatbots, you can be able to give timely and automatic help to your customers 24/7 without them having to speak to a customer support employee that may be unavailable outside working hours.
In addition, virtual assistants such as Siri and Alexa have greatly improved the utility of smart devices through voice recognition software.
Improves the accuracy of the output
Human annotated data is usually error-free due to the extensive number of man-hours that are put into the process. Through data annotation, search engines can provide more relevant results based on the users’ preferences. Social media platforms can customize the feeds of their users when annotation is applied to their algorithm.
Generally, annotation improves the quality, speed, and security of computer systems.
Final Thoughts

Data annotation is one of the major drivers of the development of artificial intelligence and machine learning. As technology advances rapidly, almost all sectors will need to make use of annotations to improve on the quality of their systems and to keep up with the trends.
If you’re looking for reliable annotated data for your upcoming project, get in touch to see our data annotation services geared to save you time, money, and effort. We also help businesses make their AI projects multilingual with our translation services in 55+ languages.